Table features
In this documentation, we will explore various optional table features that can be utilized to enhance the behavior of your database tables in Genio.
These features include table types, cascading actions, and conditional recalculation. Understanding and implementing these features can help you optimize your database structure, maintain data integrity, and improve the overall performance of your application. We will discuss each feature in detail, providing insights into their advantages, limitations, and practical applications.
Topics
Table type
Tables can be defined according to four different types:
- Table
- Partition (Not implemented)
- View
- Custom
View
A view is the result set of a stored query on the data, which the database users can query just as they would in a persistent database collection object. This pre-established query command is kept in the database dictionary. Unlike ordinary base tables in a relational database, a view does not form part of the physical schema: as a result set, it is a virtual table computed or collated from data in the database, dynamically when access to that view is requested. Changes applied to the data in a relevant underlying table are reflected in the data shown in subsequent invocations of the view. In some SQL databases, views are the only way to query data.
Advantages
- Views can represent a subset of the data contained in a table; consequently, a view can limit the degree of exposure of the underlying tables to the outer world: a given user may have permission to query the view, while denied access to the rest of the base table.
- Views can join and simplify multiple tables into a single virtual table.
- Views can act as aggregated tables, where the database engine aggregates data (sum, average etc.) and presents the calculated results as part of the data Just as a function can provide abstraction, so can a database view. In another parallel with functions, database users can manipulate nested views, thus one view can aggregate data from other views. Without the use of views, the normalization of databases above second normal form would become much more difficult. Views can make it easier to create lossless join decomposition.
Create a table view
In this section we describe the necessary steps to create a table view.
Create the view query
The query must be configured in the query definition. You can define an SQL query in Definitions > Manual Code > Queries and add a name and your query implementation. By default Genio systems are executed in SQL Server and only this query implementation is required. The query implementation should ensure the following guidelines:
- The primary key should be unique
- An integer field that corresponds to the zzstate must exist
- The field names must match the table names
- Data should come from one of the source tables, when possible
View dependencies
In case you have views that depend on views, you can use the query name to ensure the correct creation order during reindexation. Genio creates the queries sorted by the query id name, which can be used to ensure that the a view foo is created before a view bar.
Cascading actions
In order to maintain integrity, Genio does not allow, by default, the duplication or elimination of records (domain A) that are related with another domains (domain B).
On delete
By default you can only delete a record in the application when all the references for that record have been removed. For example, if I have a table named State that references Country, you can only delete a Country once all states have been deleted. However there are a few ways to change this behaviour. In the table definition of the area you want to delete you have an option called Delete on with the following options:

Delete
In the table Country you can add an option to delete the table State. This way, when you delete a Country, all states of that country will be automatically deleted.
Now let's say that the States themselves have another table below called Provinces. In this case a country won't be deleted because the state had dependencies. To avoid this problem you can add the same definition to the State table, creating a cascading deletion. I.e. when you delete a Country, it will also delete all States of that country, and all Provinces of those States.
Delete if new
Sometimes you want your users to verify each dependency, but want to facilitated the cancelation when inserting a new record. For this cases you have this option, which will only provoke a cascade deletion if the record is being inserted for the first time.
Clear
If you don't wan't to delete the records below but don't want the user to have to check every dependency, you can choose this option. This will basically clear the reference of the lower records. I.e. in the example above, when deleting a Country the record will be deleted and all States will be perserved, but they will no longer reference any country.
Clear if new
Same as delete if new but with the clear behaviour.
Remarks
- The definition should be consistent across areas.
- You can add the definition in any area of Country but must choose the domain of State.
On duplicate
By default you can only duplicate a record in the application at a time, by going to where it is located and using the duplicate buttons. However there is a way to automatically duplicate the lower table record's when duplicating the corresponding connected records. In the table definition of the area you want to duplicate you have an option called Duplicate on.


Table
This is where you choose the area which you want the records to be duplicated. Despite the option showing every table in the project, only the lower ones will work. If a not supported table is chosen, an error will occur when a record is duplicated.
Condition
This condition allows the user to have control over when the records get duplicated. Currently a condition with field from the current table or upper tables can be set and the duplication will be decided upon that, but this is not record based, it either duplicates everything or nothing.
Remarks
- The definition should be consistent across areas.
- The duplicated table must be a lower table from the one where the definition is set.
Other features
Conditional recalculation
Since Genio 305.35, it is possible to use the recalcif condition to optimize the recalculation of certain fields and, consequently, the overall process of recalculation of formulas. Note that this field was previously used to prevent fields from being recalculated, which is not the case anymore.
There are three key moments where this optimization takes place:
Server
During field recalculation in the server, it is possible to have the necessary context to determine if the input values of the formula changed. The logic applied is the following:
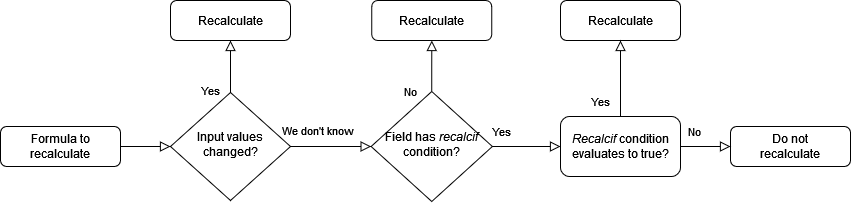
Reindex
During reindex, due to lack of context, it is not possible to determine if the input values of the formula changed or not. When it is not possible to determine if the input values of the formula changed, we assume that they did not change. With that in mind, the logic applied to the server can be simplified to:
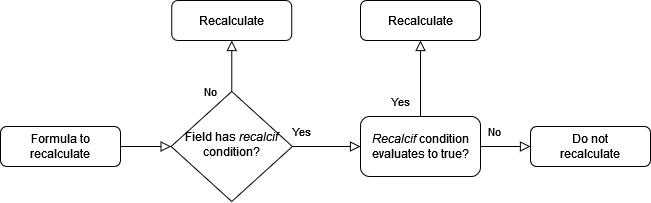
Generation
To further optimize this process, the generation of the SQL stataments that perform the field recalculation during reindex is now aware of the conditions defined in Genio:
- If the generator detects that the fields have
falsein condition to force recalculation, the corresponding SQL update statement is not generated (it would always be ignored, after being evaluated) - If the generator detects that the table has
falsein condition to force recalculation, the entire block of SQL update statements that recalculate the formulas of the table fields are not generated (they would always be ignored, after being evaluated)
Conclusion
In this documentation, we have explored various optional table features that can enhance the behavior of your database tables in Genio. These features include table types, cascading actions, and conditional recalculation.
By understanding and implementing these features, you can optimize your database structure, maintain data integrity, and improve the overall performance of your application. We hope this guide has been helpful in mastering these optional table features, and we encourage you to apply this knowledge to your projects.